Prototypical Networks for Few-Shot Learning
Introduction
Prototypical Networks for Few-Shot Learning, published in 2017 out of Richard Zemel’s group, sits between two related domains: metric learning, meta-learning (of which few-shot learning is a subset). In this post, I’ll give an overview of these domains, highlight where prototypical networks improves on existing art, and show some visualizations using UMAP and Learn2Learn, a new PyTorch framework for meta-learning.
While I was putting togther these overviews, I found the following blog posts to be quite insightful. They give more depth in the areas that I’ll touch on:
- Meta-Learning: Learning to Learn Fast by Lilian Weng. Everything she writes is worth reading!
- Towards Annotation-Efficient Learning: Few-Shot, Self-Supervised, and Incremental Approaches by various researchers. Incredible amount of excellent content!
- Learning to Learn by Chelsea Finn.
Metric Learning
Metric learning asks an algorithm to produce a latent space, governed by a metric, that encodes semantic simiarlity between embedded objects. The paper gives special mention to two metric learning predecessors that inspired the neural network transform for embedding ( Learning from One Example Through Shared Densities on Transforms) and the nearest class mean approach (Distance-Based Image Classification: Generalizing to new classes at near-zero cost).
Although not mentioned explicitly in the paper, Siamese Neural Networks for One-Shot Image Recognition is a kind of metric learning predecessor for prototypical networks as well. Siamese networks embed all support objects and the query object into a latent space and do a pairwise comparison between the query and all other support objects. The label of the closest support object is assigned to the query. Prototypical networks improve by 1) requiring comparisons between query and support centroids, not individual samples, during inference and 2) suffering from less sample noise by taking the mean of support embeddings.
Meta-Learning
Meta-learning asks an algorithm to produce a meta-learner that can learn successfully on unseen datasets, rather than unseen samples of seen datasets. The scope of this field is vast and stretches beyond classification and label efficiency to intersect with reinforcement learning, hyperparameter tuning, and architecture search among others.
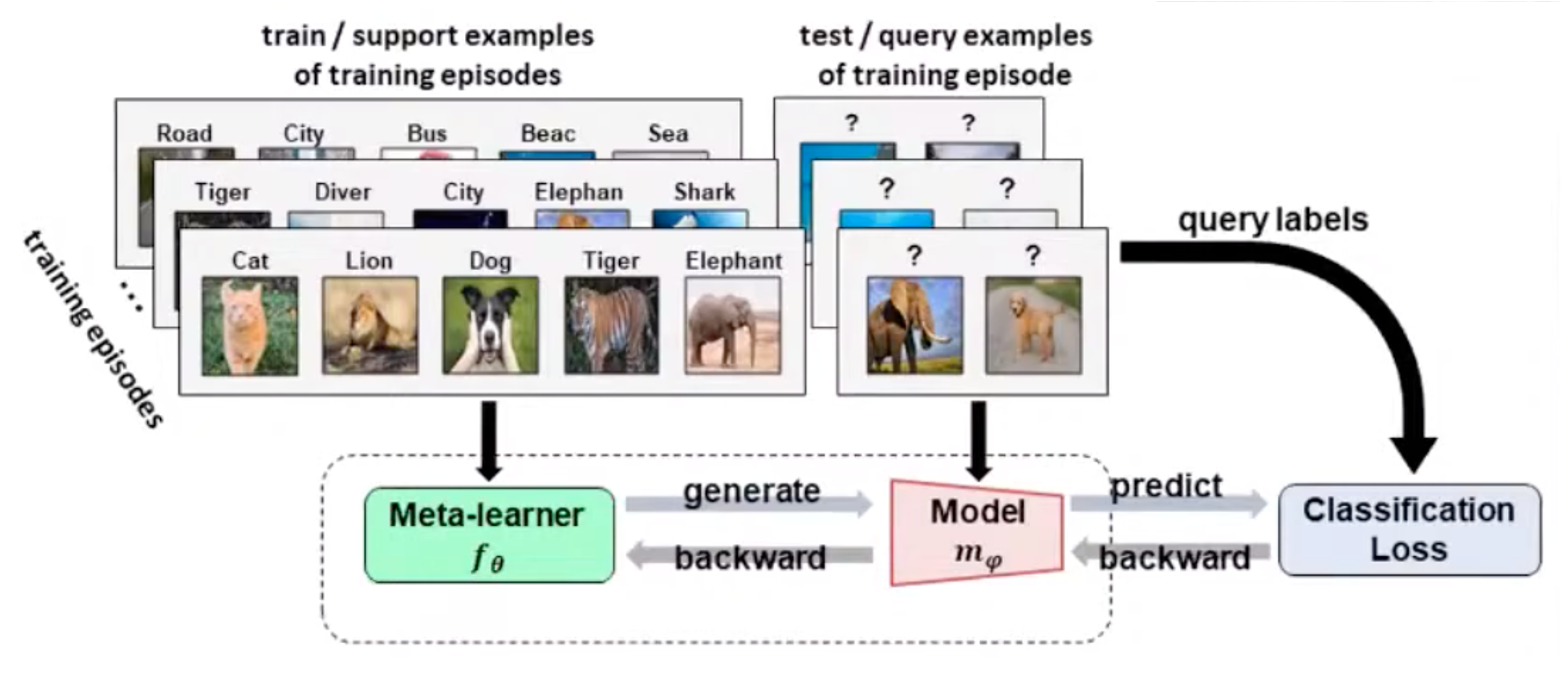
Matching Networks for One-Shot Learning is the meta-learning predecessor of prototypical networks for image classification. It transforms a query image and support images and compares them using an attention mechanism.
Prototypical networks extend matching networks by allowing few-shot and zero-shot learning instead of just one-shot learning.
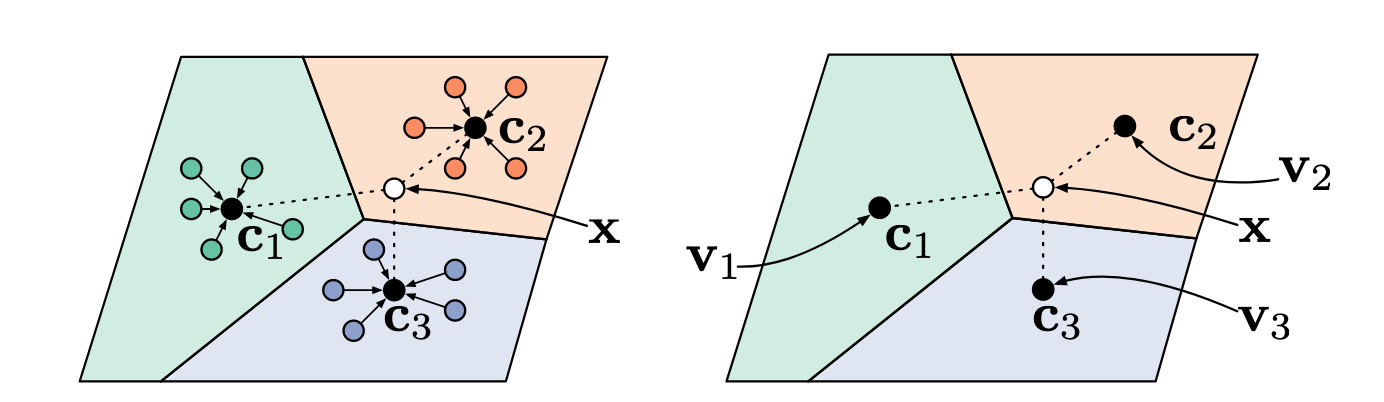
Code
Learn2Learn is the most popular meta-learning PyTorch framework on Github at the time of this writing. It boasts excellent documentation and examples that work out of the box, such as this prototypical networks example on Mini-imagenet.
Mini-imagenet is a dataset proposed by the authors of Matching Networks specifically for evaluating few-shot classification methods. In total, there are 100 classes with 600 samples of 84×84 color images per class. These 100 classes are divided into 64, 16, and 20 classes respectively for sampling tasks for meta-training, meta-validation, and meta-test.

In the prototypical networks paper, the authors cite test set accuracy of 49.42±0.78% for 1-shot, while Matching Networks clock in at 43.56±0.84%. Because the architecture is equivalent for 1-shot evaluation, the Snell et al cite the prototypical networks’ use of the Euclidean distance rather than the Cosine distance used in Matching Networks as a main reason for 6-point improvement.
Visualization Results
The promise of prototypical networks’ metric learning implementation is a semantically-encoded latent space. I trained a 4-layer CNN using Learn2Learn’s out-of-the-box example and achieved 40.11% accuracy on the validation set after 47 epochs. I chose UMAP over TSNE for visualization to optimize for speed (12,000 images in the test set). For contrast, I first visualized the flatten original images and the PCA transform with 4 components. The training and visualization code can be found in this repo.
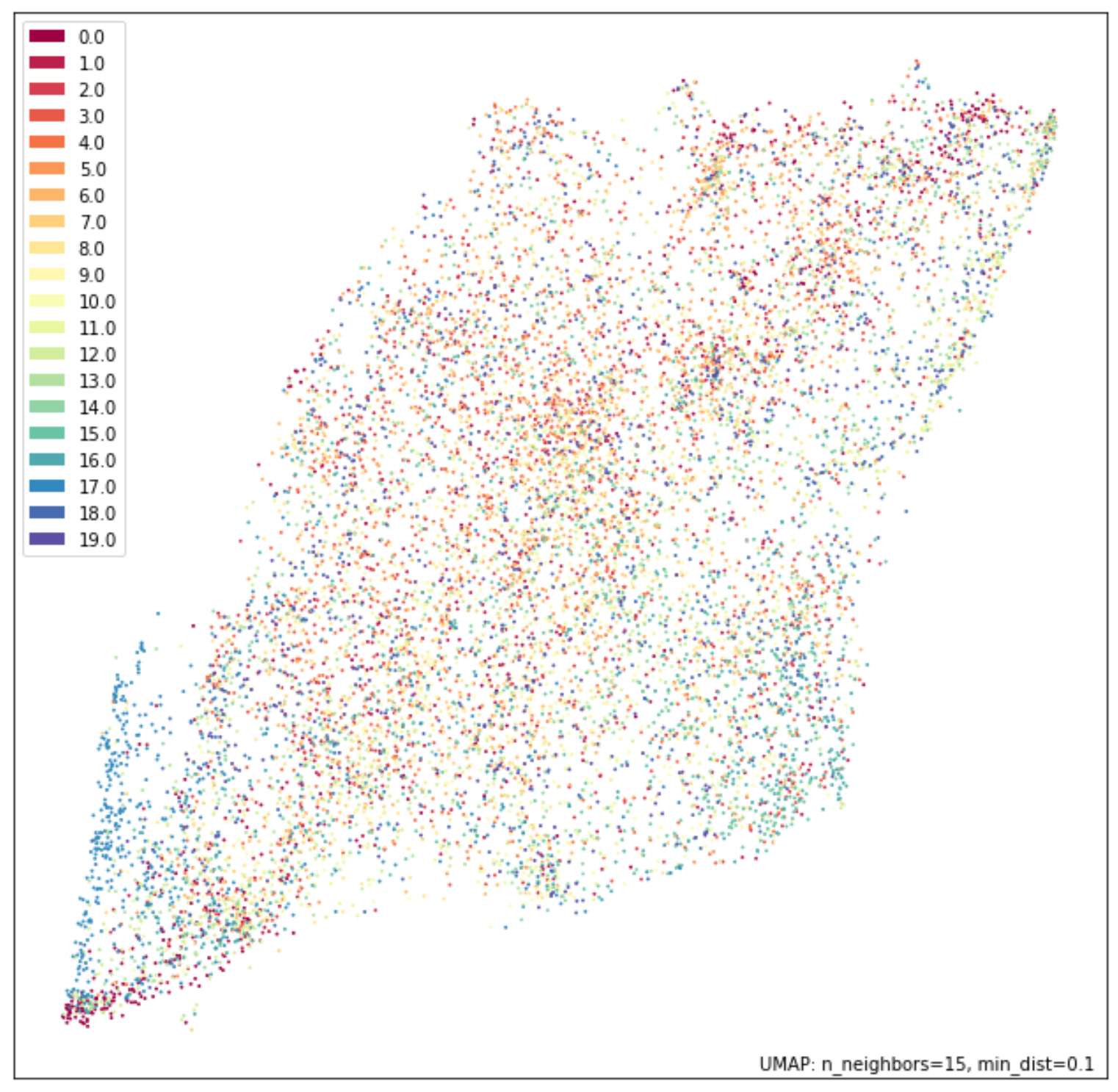
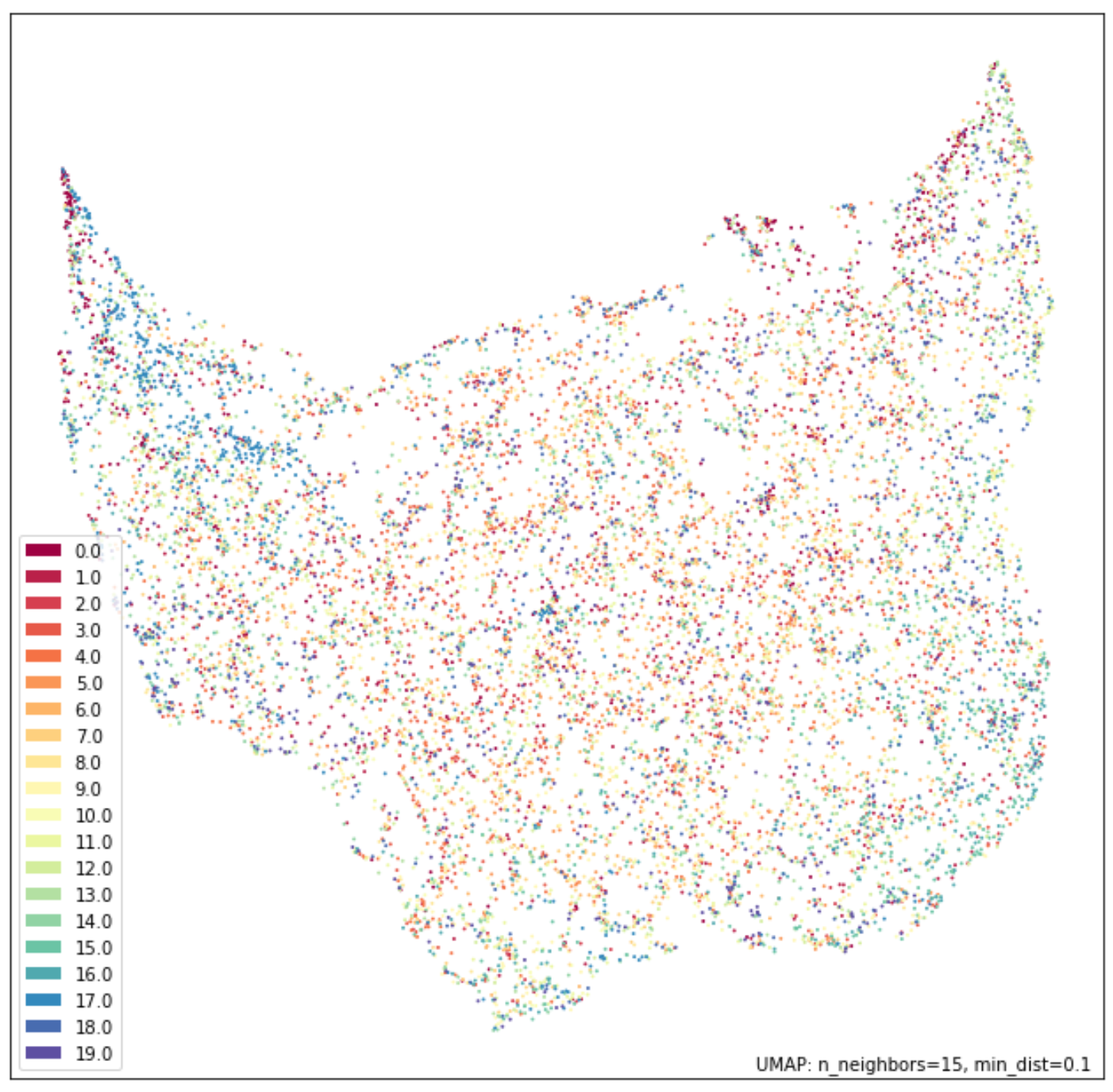
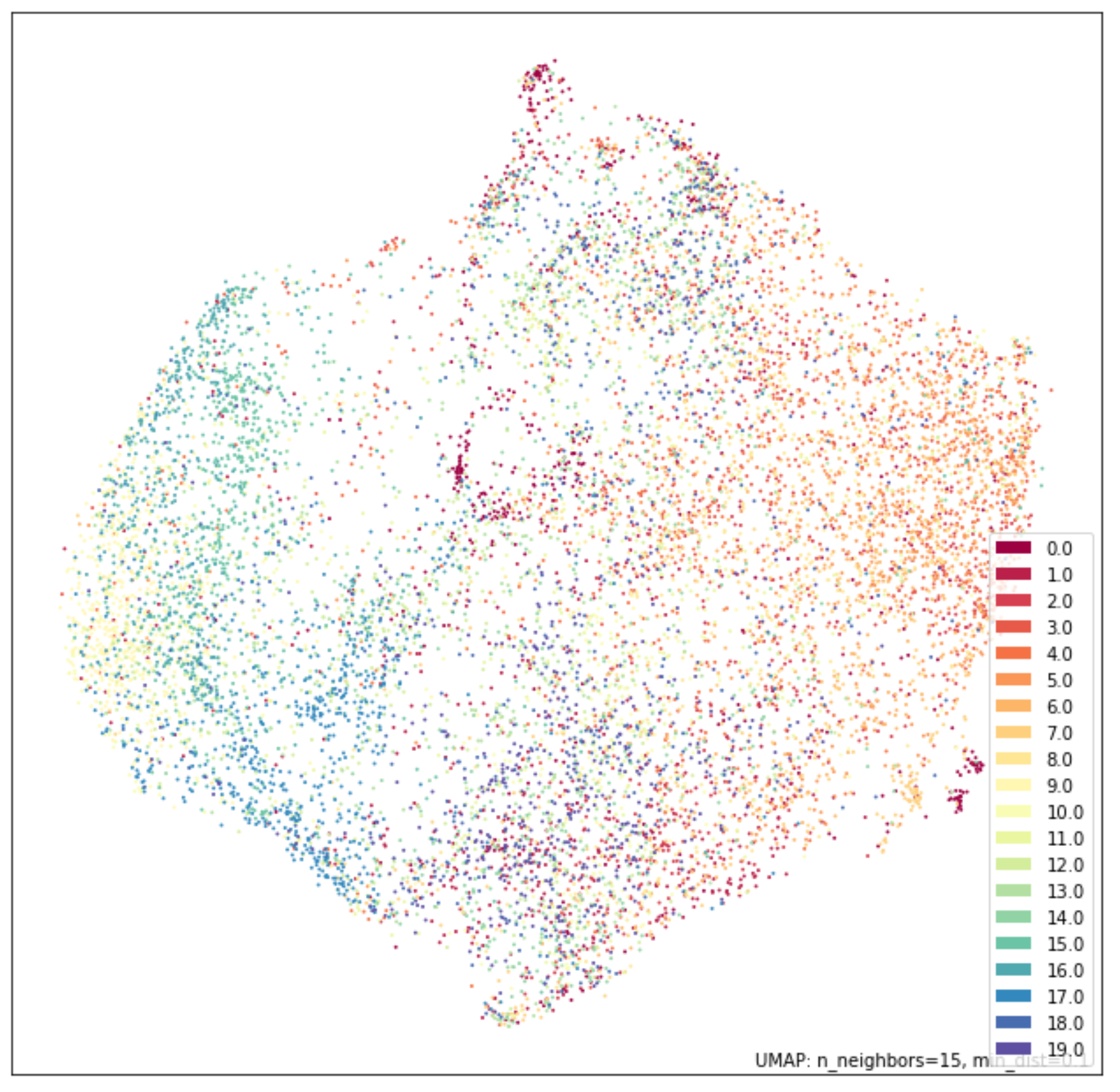
The promise holds true! Prototypical networks can successfully embed objects with semantic intent. Another interesting comparison would be using the same network trained on the meta-training set without meta-learning principles applied. Additionally, an interesting domain extension would be towards natural language.
Object Detection
Speaking of extensions, my initial goal for this deep dive was to find a suitable method for label-efficient object detection for my work at Proofpoint. However, after looking through the recent literature, simpler approaches seem to be yielding superior results. For instance, Frustratingly Simple Few Shot Object Detection fine-tunes the last layer of a Faster R-CNN network in a two-stage sequence for state-of-the-art results on PASCAL VOC, COCO and LVIS.
Acknowledgements
Thanks to the ML Labs organization at Proofpoint for engaging with my lightning talk on this topic several months ago.